Kubernetes
Info
Si une node à changer d’addresse (après un reboot par exemple), il faut recover le cluster. Cet Article explique les étapes à suivre.
Terme qui provient du Grecque qui signifie: pilote. C’est une analogie en lien avec les containers, qui peuvent avoir une signification maritime. Kubernetes est le bateau qui gère les containers!
Architecture
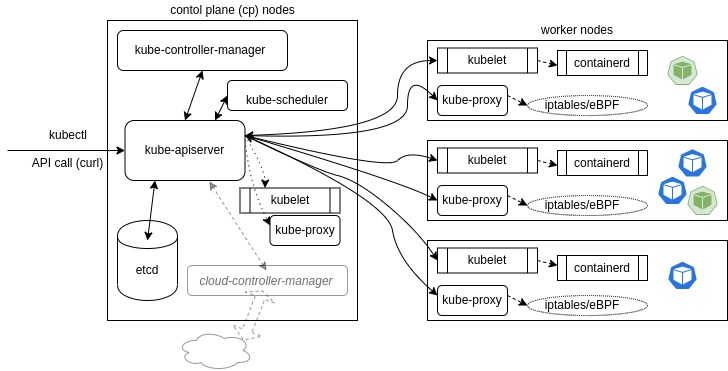
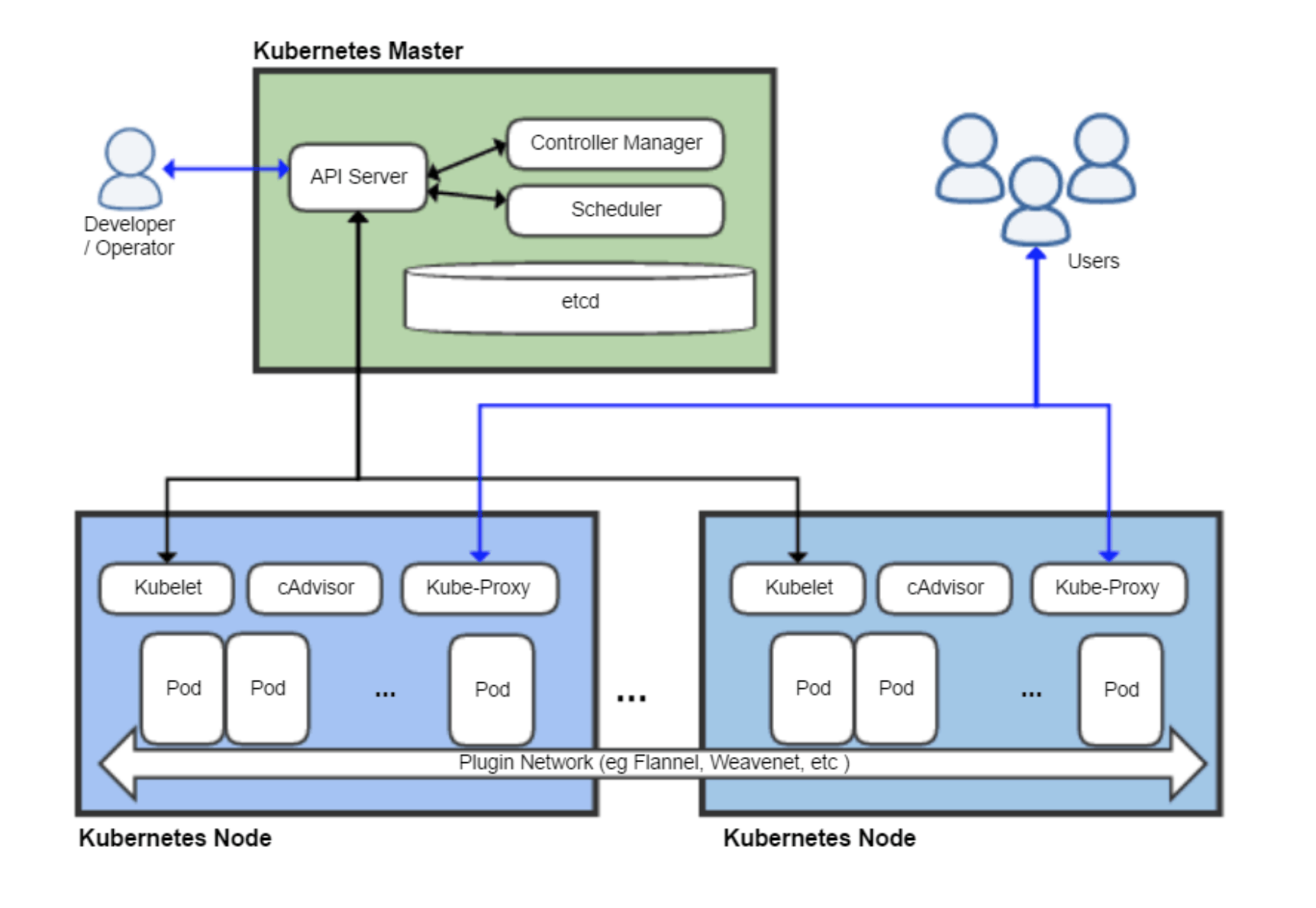
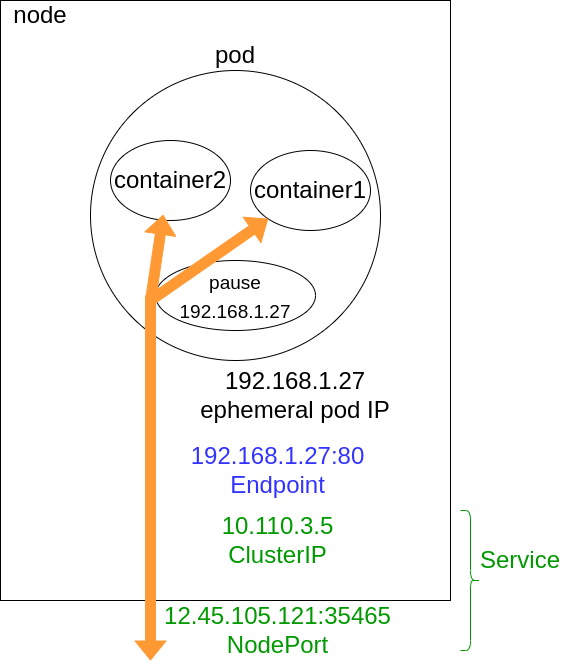
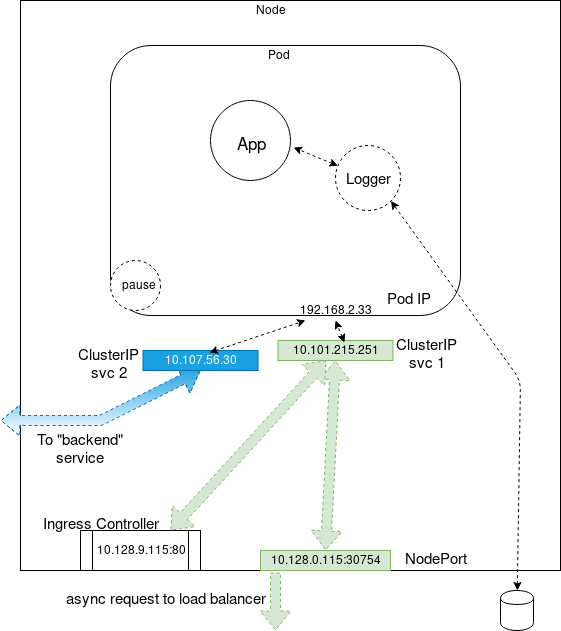
En Gros
Question
Pour une description plus en détail, voir ici
Ils existent deux rôles basique pour les nodes, les workers nodes et les masters nodes. Il existe plusieurs agent sur les master, comme Kube-Apiserver ou Kube-Scheduler. Lorsqu’un utilisateur entre une commande avec kubectl, il fait un appel à l’API de Kubernetes via Kube-Apiserver. Ce serveur vas gérer où la requête doit se rendre. Ce serveur sert également à garder le status de la base de donnée et est le seule à interagir avec etcd.
Sur les workers node, c’est Kubelet qui vas gérer les containers, leurs images et la configuration. Il envoie également le status des objets lors de leur création.
Déploiement
Il est nécessaire sur chacune des nodes d’avoir un Container Runtime valide. Ensuite, il est possible de configurer le CRI pour utiliser celui-ci. Pour créer un cluster Kubernetes initialement, il est nécessaire d’utiliser les outils kubeadm et kubectl. Pour initialiser un cluster, il faut exécuter kubeadm init dans notre Control Plane et ensuite kubeadm join sur nos workers nodes. Ensuite, il est nécessaire d’installer un plugin de networking pour que les pods puisse avoir accès au réseau. Ils sont nommés les CNI. Il en existe plusieurs, il faut donc choisir selon les besoins courant. Il est nécessaire d’enlever toutes Partition Swap sur la machine pour des raisons de performance.
Le système d’exploitation revient à sa complexité de garder à jour. Kubernetes roule sur tous les OS majeur (Debian, CentOS), même certaines distributions optimisé pour container.
Types de Configurations
Il existe quelque type de configuration possible lors de l’installation.
- Single Node Utilisé surtout pour tester Kubernetes et comprendre comment sa fonctionne
- Single Head Node, Multiple Workers Le control plane consistera d’une seule node. Chaque worker se connecterons dessus. Ceci résulte en 1 seule Etcd, donc si le serveur crash, des données peuvent être perdu
- Multiple Head Nodes (HA), multiple workers Setup où le Control Plane peut s’exécuter en High Availability. L’apiserver se fera load-balanced et le scheduler et controller-manager électrons un leader. Si une instance d’Etcd roulent sur chaque node, il sera résistant au crash.
- Etcd (HA), Head Nodes (HA), multiple workers Même setup qu’en 3, sauf qu’Etcd est également configurer pour résister au crash.
Déploiement Autonome
Il existe des outils afin de permettre le déploiement de cluster plus facilement grâce à des technologies d’automatisation. Par exemple:
Ils ne sont pas tous recommandé d’être utilisé en production, mais ils permette de mettre en place un cluster rapidement en utilisant des outils d’automatisation (genre Ansible).
Outils
Il existe plusieurs outils afin d’utiliser Kubernetes. Notamment Kubeadm et Kubectl. Kubeadm est utilisé pour permettre une initialisation plus simple d’un cluster. Kubectl est utilisé pour permettre une interaction plus simple avec les objets d’un cluster.
Objets
L’API Kubernetes est composée de plusieurs objets. Chacun permette des fonctionnalités différentes. La liste complète ce retrouve sur la page de référence de l’API Kubernetes.
Par exemple:
Pour une liste complète de l’API, voir ici.
References
- LFS258